
Cognitive Ergonomics
Can we fix our Procrustean toolkit without permanently warping ourselves in the process?
We’re back to weekly posts until morale improves.
Last Friday, I went to the new-to-me and apparently secretive Foo Camp, hosted by O’Reilly Media. As a bit of a pun fiend, I can appreciate the name. The original event happened shortly after the tech bubble popped in 2000. In response to widespread layoffs, Tim O’Reilly and some buddies decided to throw a conference (their idea of a party). There, people could share what weird and wacky things they were doing in their newfound free time. According to sources familiar with the matter, planners of the inaugural event first named it after the military-turned-software acronym FUBAR – Fucked Up Beyond All Recognition. This morphed into Foo Camp, where Foo now stands for Friends Of O’Reilly.
I guess they’ve got a friend in me. I received an invite to share my knowledge about protocols and field-building. On Day 2 of Foo, I gave a short talk on cognitive ergonomics – applying ideas from traditional occupational health and safety (OHS) to the context of AI tools. My hope was to take a meaningful step towards an applied science of fitting these new tools to the people that use them, rather than the other way around. The central provocation of my talk was:
“What are the repetitive strain injuries of working with large language models, and have we figured out how to avoid them?”
At least 30 of the ~150 campers tracked me down over the weekend to talk about my talk. Which was great, since I’m a pretty reluctant networker. And because of all of those excellent conversations I felt the need to extend my lightning talk into an article. My colleague Venkatesh Rao and I are also working on a DSM-style database for cognitive ergonomics of AI. If you feel like helping, feel free to share some anecdotes – whether symptoms, hazards or actual protocols for improving cognitive ergonomics.
Procrustean Tools
I was on the lookout for AI vampires when I flew into San Francisco last week. Sure enough I saw plenty: bags under their eyes, terminal sessions open, Clawd dispatch open on their mobile device… and avoiding direct sunlight.
When workers adopted the typewriter, they did so for its amazing efficiency. But the early versions of this tool were mechanical, so buttons needed a lot of force. After extended use, writers, clerks and court stenographers began to develop carpal tunnel syndrome. To realize its potential, the typewriter required its users to act in unsustainable ways. Technological developments have always impacted workers. Today, we have a new type of computer. To promote the wellbeing of workers and get the most out of AI tools, we should address these impacts as soon as possible.

The typewriter is a case of classical ergonomics. User interfaces of large language models (LLMs) and world models don’t present any direct hazards that we didn’t already know about. Office workers are prone to musculoskeletal and metabolic disorders due to the nature of their work. What you might not know is that the top work-related risk factor in the 21st century is stress, especially from long working hours. That’s a problem for workers, employers and insurers. Stress alone is unhealthy, but adaptations to stress – smoking, drinking and hyperpalatable food – are often made outside of the workplace and can compound the original issue. Traceability is the Achilles’ heel of contemporary workplace health improvement initiatives.
We are entering even trickier territory now: cognitive ergonomics. When tracing root cause and responsibility is such a difficult problem, workers are left with little choice but to create health and safety protocols without permission, relying on a mix of empirical evidence and peer support.

Before I go further, it’s worth saying that I like using LLM tools. We wouldn’t be able to run and scale the Protocol Institute without them. They’ve been instrumental in my work as both an Idea GuyTM and an Execution GuyTM for the past three years. Despite the utility, I sometimes wonder if these tools are like back braces – if I use them all of the time, won’t my strength atrophy?
It’s been a while since I’ve heard “AI is a bicycle for the mind” used in earnest, but that tagline is illustrative. Bicycles are fun, but obviously they’re a little dangerous. So what’s the best way to reduce your risk of a cycling accident?

The best way to reduce your risk of a bike crash is to never get on a bike.
But that’s just one way of thinking about safety.
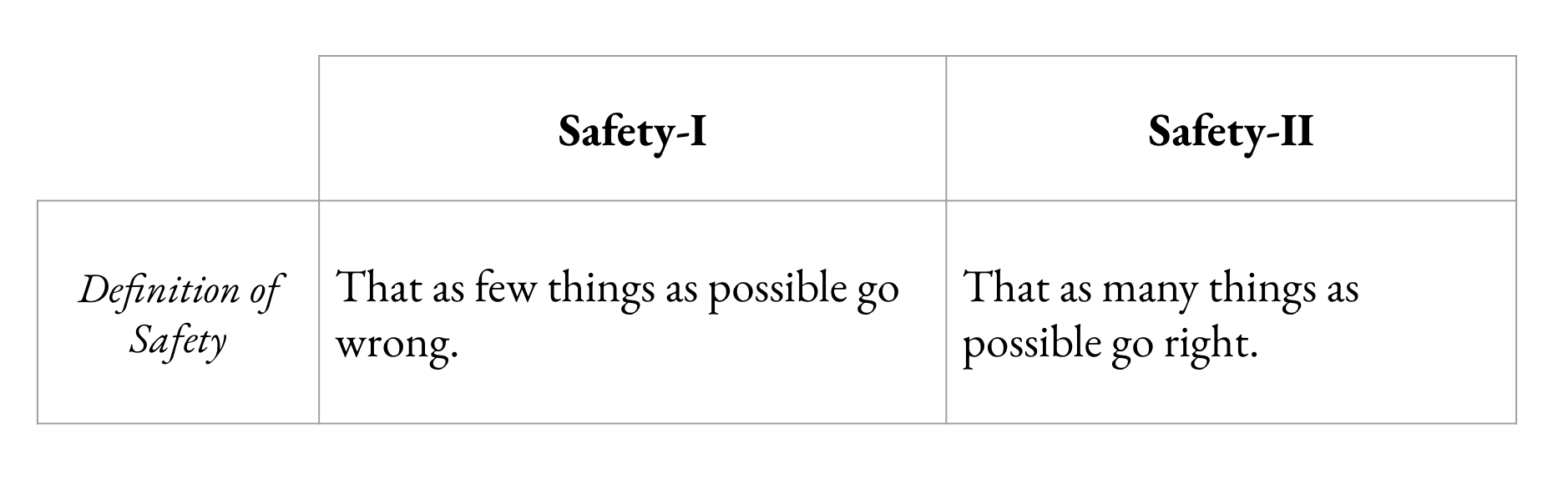
Typewriters were never just going to go away. Nor email. Nor LLMs. While we must strive for improved occupational health and safety outcomes, we should also keep in mind: while all accidents are preventable, it is not possible to prevent all accidents. Cognitive ergonomics for AI is about figuring out how we can all ride our bicycles more, not less. It’s in the long-term interest of both AI labs and workers if these new tools don’t disfigure practitioners.
Agent, not agentic
I’m an OHS professional, not a philosopher. Whenever people bring up AGI, runaway self-recursive improvement or anything related to existential risk, it’s time for me to Irish exit. That sort of debate is categorically different than the kind you find among AI adopters in the real world. Accordingly, it’s useful to frame LLMs not as agents in the principal-agent sense, but as agents in the chemical sense. Different chemical agents possess different qualities that make them useful and dangerous. Acids are great for cleaning equipment, but they’re indiscriminately corrosive.

WHMIS, the Workplace Hazardous Materials Information System, protocolized the handling of potent chemical agents at work. Employees could rely on standardized symbols and procedures, allowing them to work efficiently and intelligently manage risk. Categories are clear, bounded and manageable.

We should really be thinking about how to handle AI agents safely, without atrophying our own cognitive capacity, without poisoning our knowledge with slop and without melting critical web infrastructure by accident. This is a much more tractable problem than solving “alignment” up front. It starts with figuring out how people – like you and me – use LLMs to do good work, then working hard to reduce exposure to the hazards of this new class of technology.
Another difference between cognitive ergonomics and mainstream AI safety discourse is that the latter assumes the worst about humans. That workers and individuals are malicious, unreliable and error-prone. But it’s worth asking: what makes humans error-prone? The answer is variability. Humans vary in their performance. Variability is not just a source of error, but a source of adaptability. We are only able to adopt AI at this point because workers are adapting themselves to the tools.
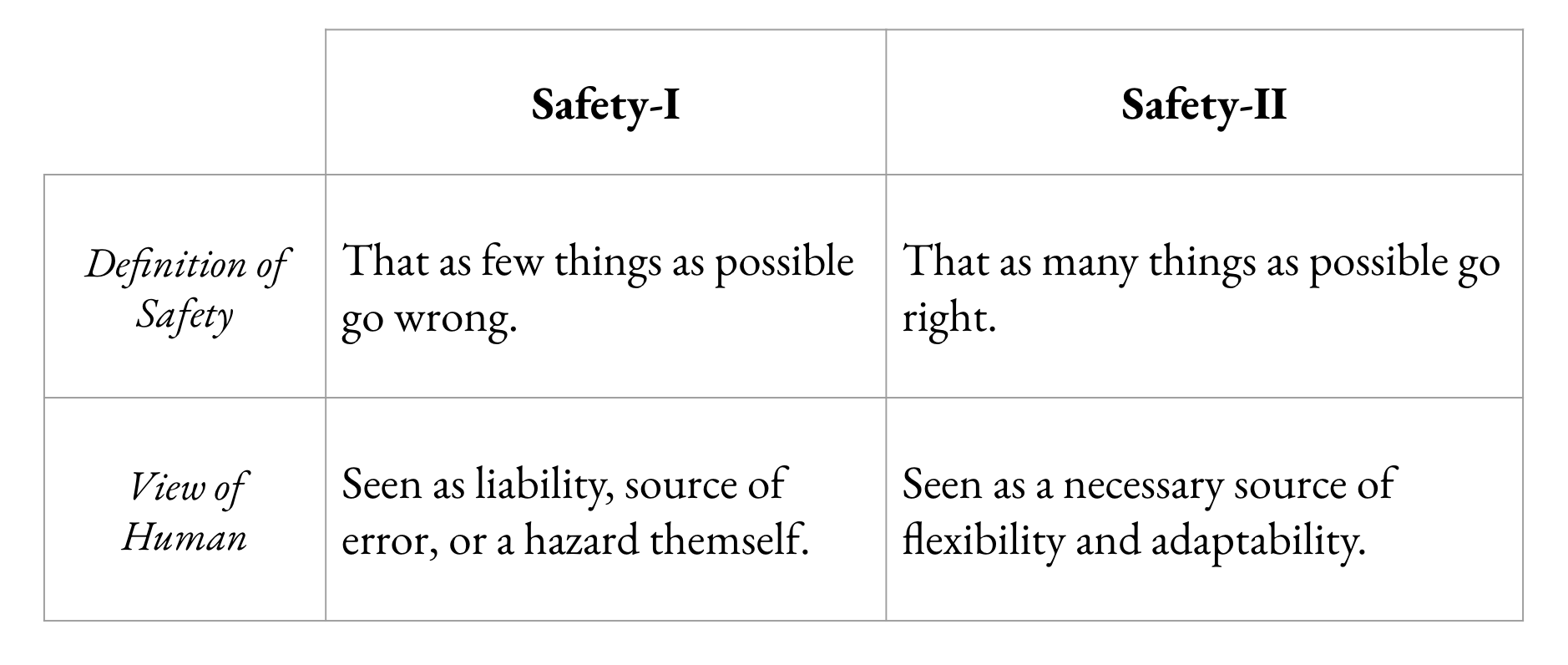
So the starting point for CogErgo is what’s going well and a positive view of human variability, rather than a full-stop attempt at solving alignment up front. (As an aside, I’m on board with Emmett Shear’s view; alignment between agents is a capability enabled by protocols.)
Studying successful AI-assisted operations (how things go right) provides context for understanding how things go wrong.
We can’t just look at the bad stuff.
Towards a manual of cognitive ergonomics for AI
There are a few kinds of syndromes or disorders that might be the result of AI tool usage. Remember that these typically appear in the context of people doing good work. It’s important that our first instinct be to manage, not solve, these problems, even if the ultimate goal is of course to remove the source of the hazard.
Some early disorders and loosely-defined protocols worth noting:
AI Psychosis – entering into distorting feedback loops with an LLM in a chat interface – protocol: contact with the real world, socializing and touching grass.
AI Vampirism – insomnia, stress, long working hours that can translate to poor metabolic and musculoskeletal health outcomes in the long run – protocol: meeting movement guidelines and reducing or managing work-related stress.
Executive Overfunction Syndrome (EOS) – domain-independent hypochondria, where users become acutely aware of how things could go wrong without a good sense of their actual probability, leading to a sense of being overwhelmed (coined by Sarah Friend) – protocol: have not heard of an effective one yet.
Default Skimming – a.k.a. atrophy of reading comprehension; LLMs produce an immense amount of text and code, which is impossible to review. In the absence of effective layers of abstraction or spot-testing techniques, workers quickly develop a habit of skimming any text they need to read – protocol: be extremely selective in what you actually read.
Rabbitholing – often caused by LLM follow-up prompts, which can take you way off tangent from your original work; a risk driver for EOS – protocol: write down intentions prior to starting up the tool.
I’d appreciate any anecdotes that you want to share, especially in the comments so others can benefit from your experience. Thanks again to everyone at Foo that came up to chat with me about this!
